




Table of contents
There are tons of Kafka articles, but I want to write a blog about it on my own style: short and full of images. There are 4 main topics to be discussed: Fundamental, Architecture, Producer, and Consumer.

Fundamental
Apache Kafka is a distributed publish-subscribe messaging system, which passes messages from one end-point to another. Kafka is also a robust queue and can handle a high volume of data.
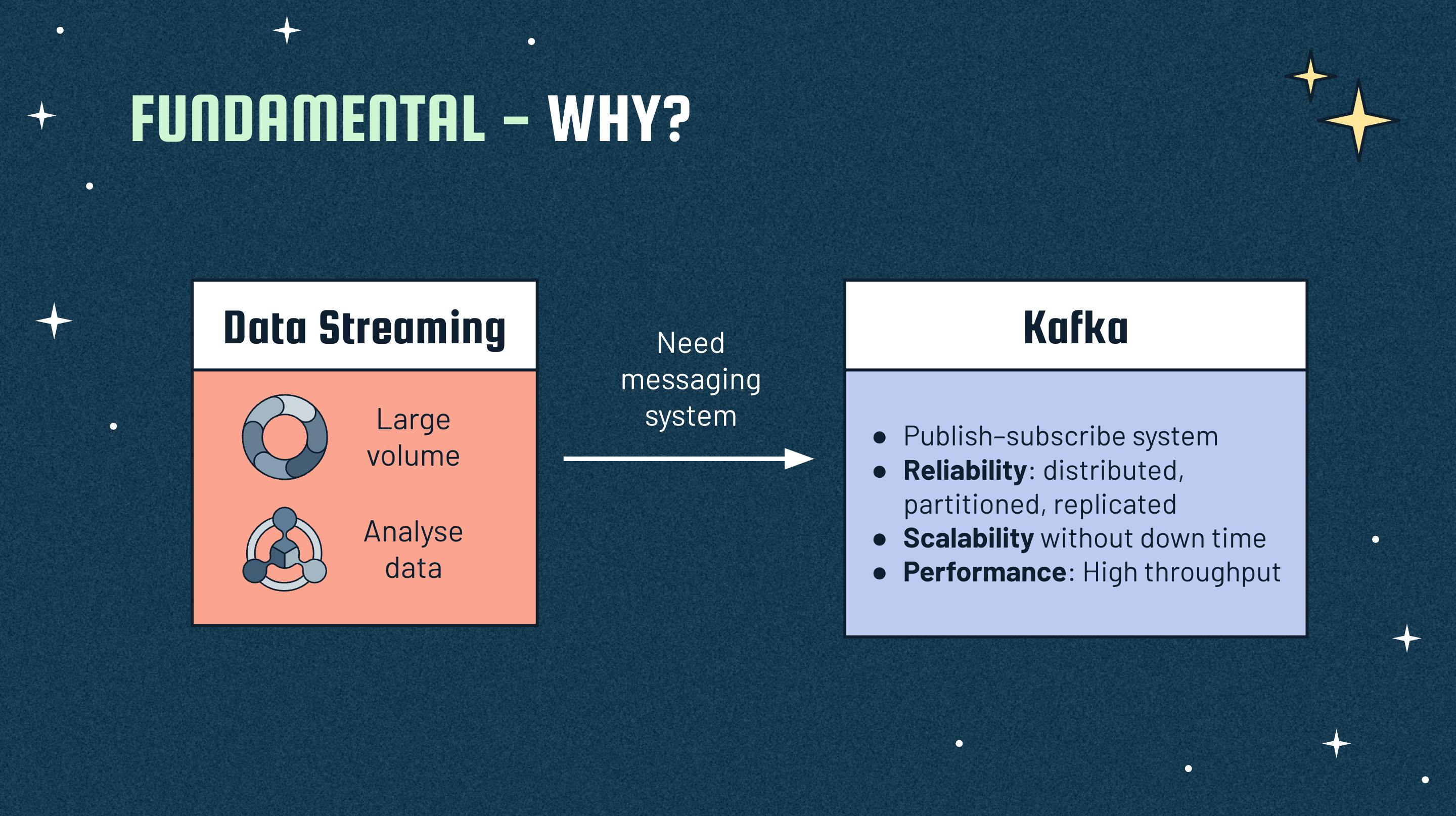
In software view, there are 4 main concepts when working with Kafka:
- Producer: Public messages to one or more Kafka topics. The messages will be appended only to the last position.
- Consumer: Subscribes to one or more topics and consume published messages.
- Topic: A place that messages of a particular category are organized in.
- Partition: A topic is a logical place and divided into partitions, which are like physical places to contain messages.
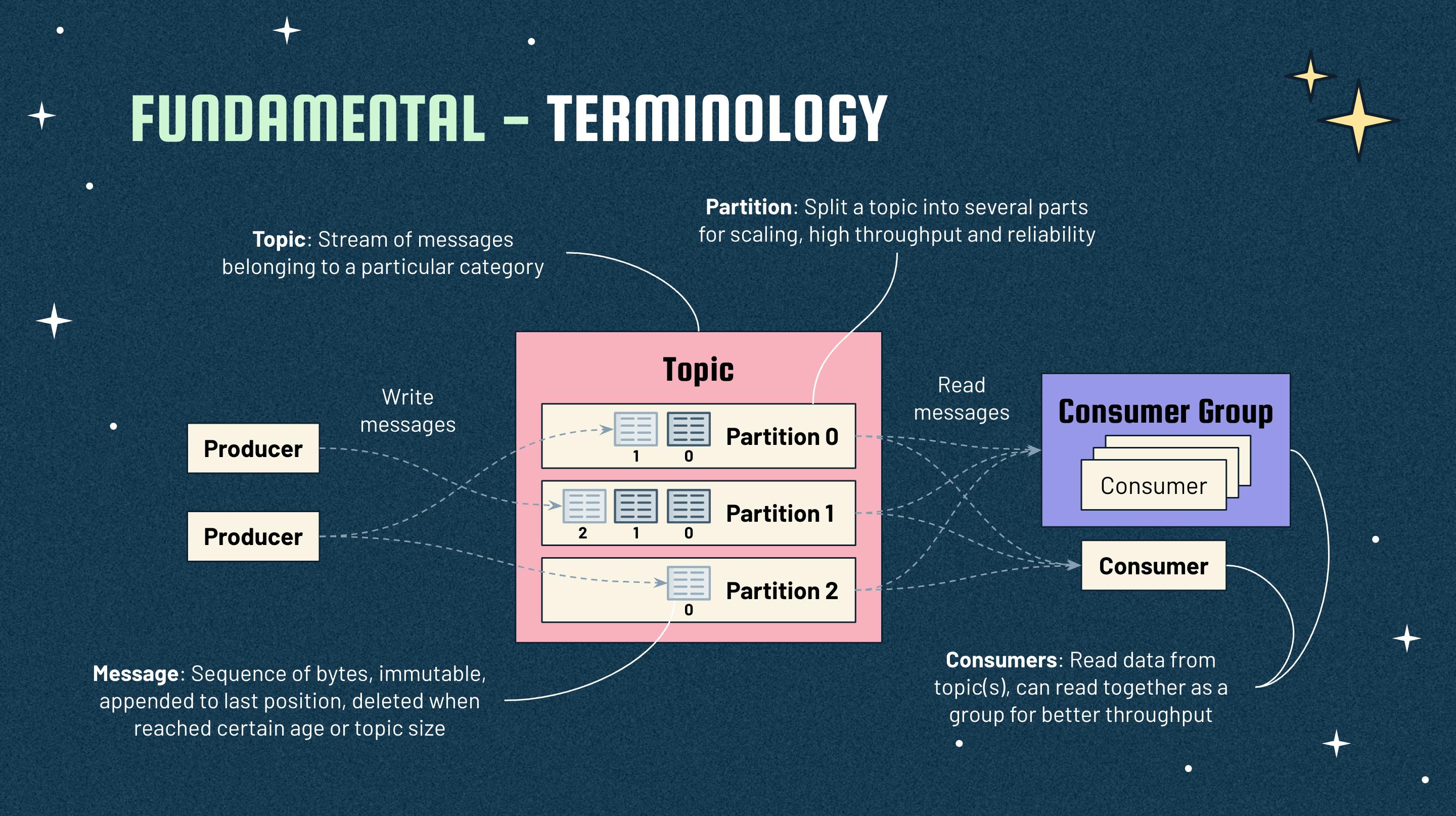
Architecture
Kafka ecosystem contains 1 or more brokers and ZooKeepers (may not required in later versions).
Brokers:
- responsible for maintaining the published data
- have zero or more partitions per topic
- can be leader or follower of a partition. Followers are never read or write data, and they just make replicas for backups of a partition. In contrast, leader can read or write data.
ZooKeeper holds metadata, e.g. available brokers, addresses and ports, which one is leader, etc. and is used for managing and coordinating Kafka broker. In later version, we may not need a ZooKeeper to run Kafka.
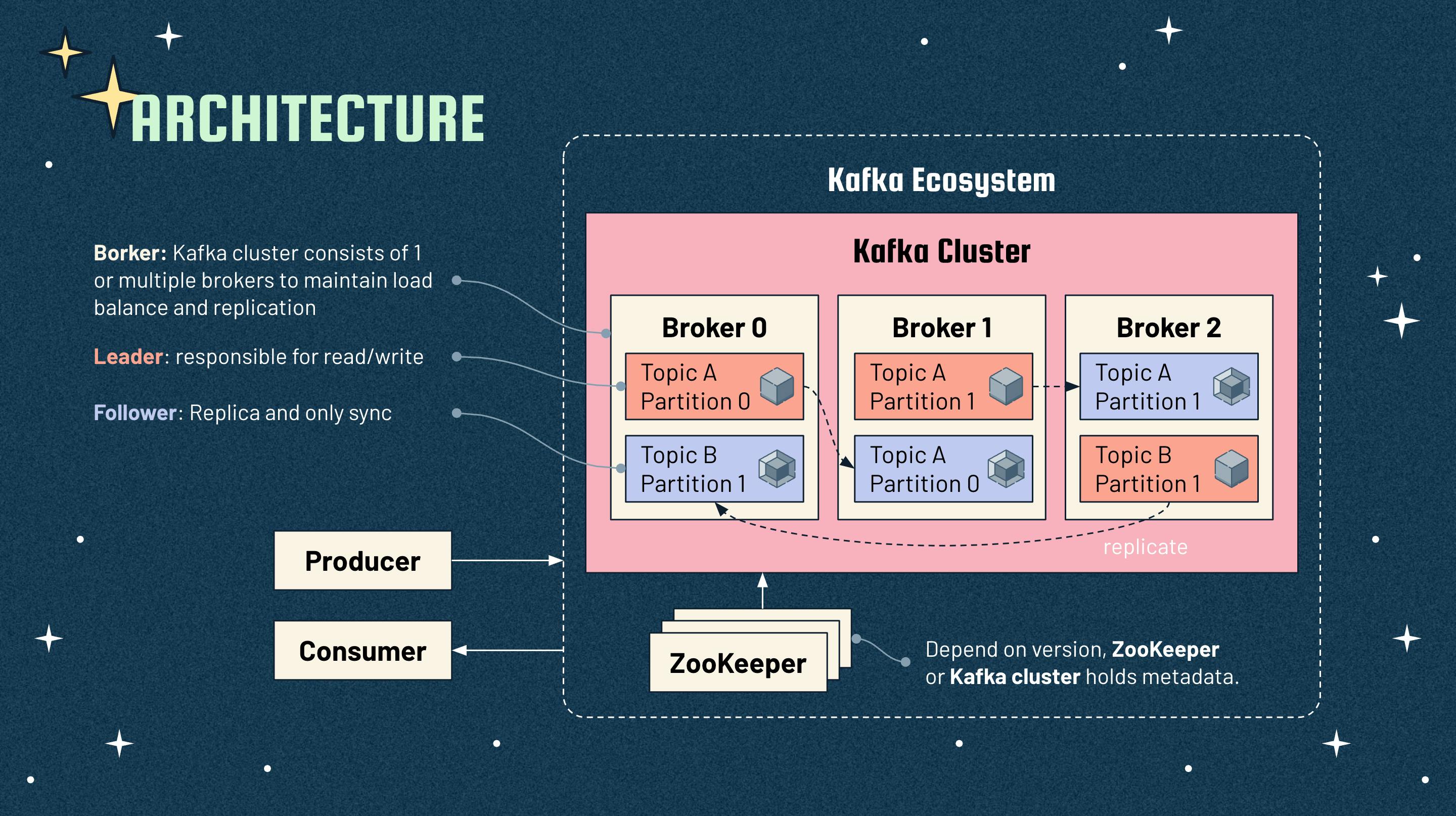
Producers
Producers write data to topics within different partitions. Producers need bootstrap servers to get Kafka metadata, then they will know what data should be written to which partition and broker. Users does not require to specify the broker and the partition.
Producers can use keys to send the messages in a specific order. Data with a key always be written into a partition, which message order is maintained strictly. Without keys, data will be distributed among partitions in round-robin manner, and this does not guarantee order when reading.
Producers can control the process of Kafka response through ACK. They can wait for leader received the data (ACK=1), or both leader and followers received the data (ACK=all), or even not wait for anything (ACK=0).
Consumers
Consumer can read data from a topic alone or be grouped with others to increase read throughput. The scaling ability and high performance of Kafka depend on partitions and number of consumers in a group. We can add or remove partitions and consumers at anytime, and Kafka will reassign partitions to consumers (workload rebalancing). One consumer can read multiple partitions, but 1 partition is only ready by 1 consumer.
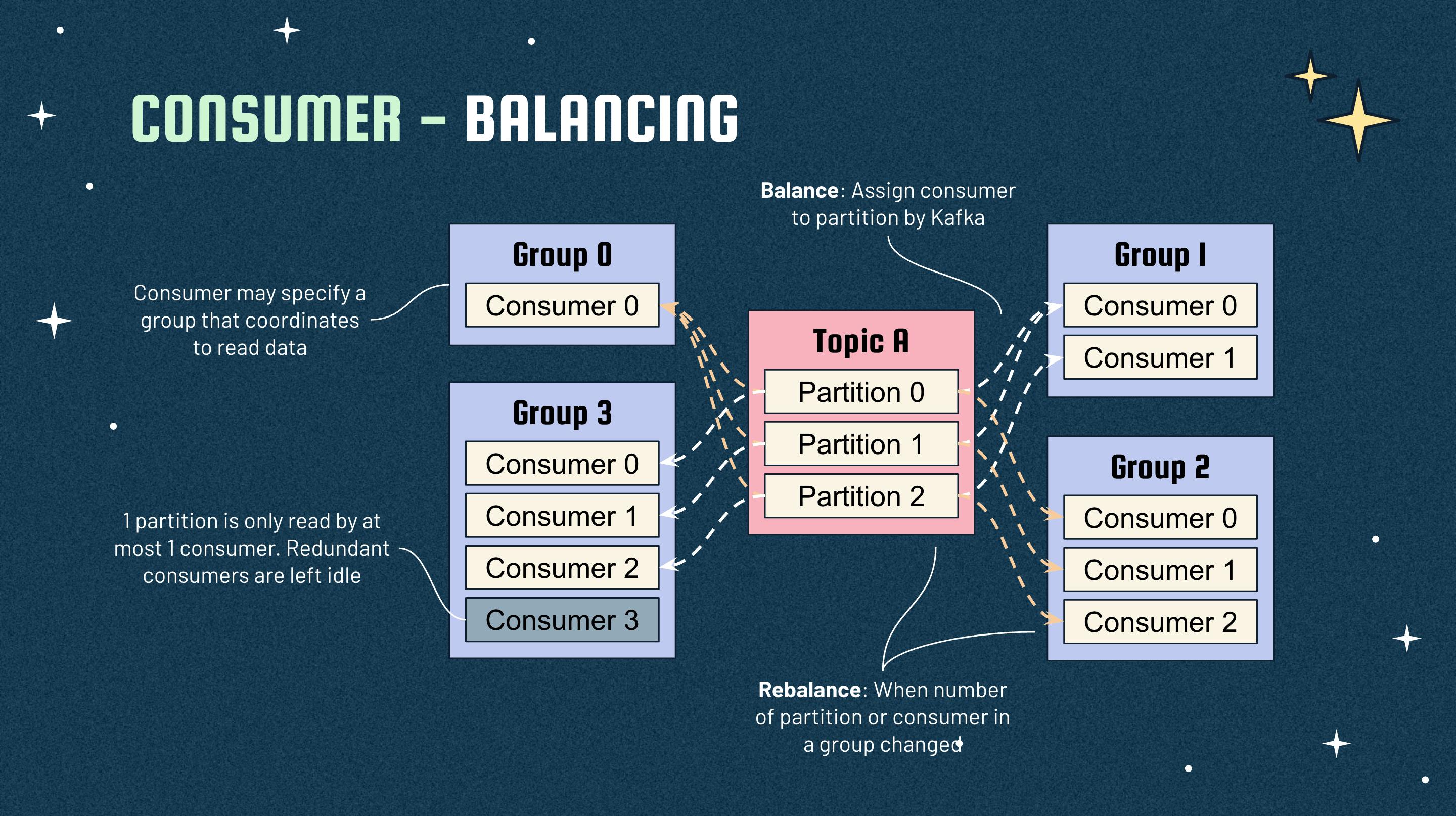
There may be multiple consumer groups reading a topic. Each consumer group will have its own state, which means it will read from the point it left after shutdown/restart or rebalancing process. The state is the latest offset that data is processed. Consumer may commit its offset manually or Kafka can trigger automatically at each interval (default: 5s). Manual commit can be done synchronously (wait successful responses from Kafka) or asynchronously (process next items and ignore response results). Depending on commit method, we can achieve some effects of delivery: no guarantee, at most once, at least once, and exactly once.

That's it. Keep the content short. The target is short but understandable. Thank you for reading my blog.